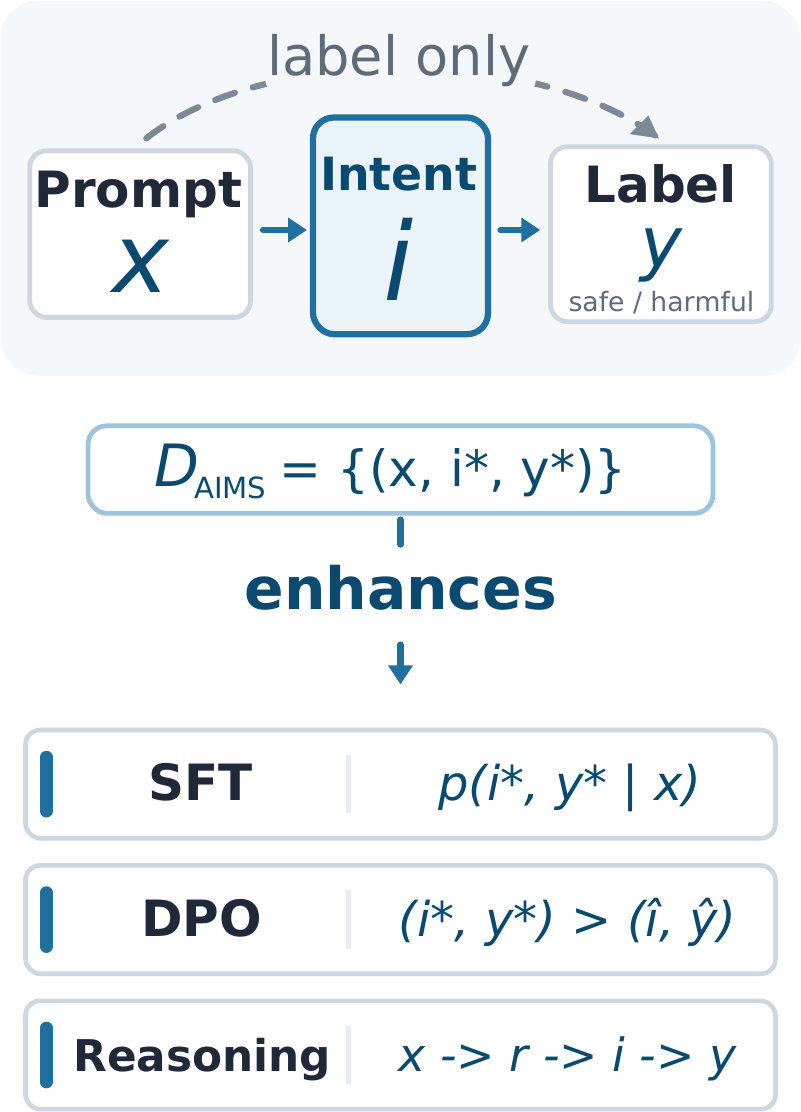
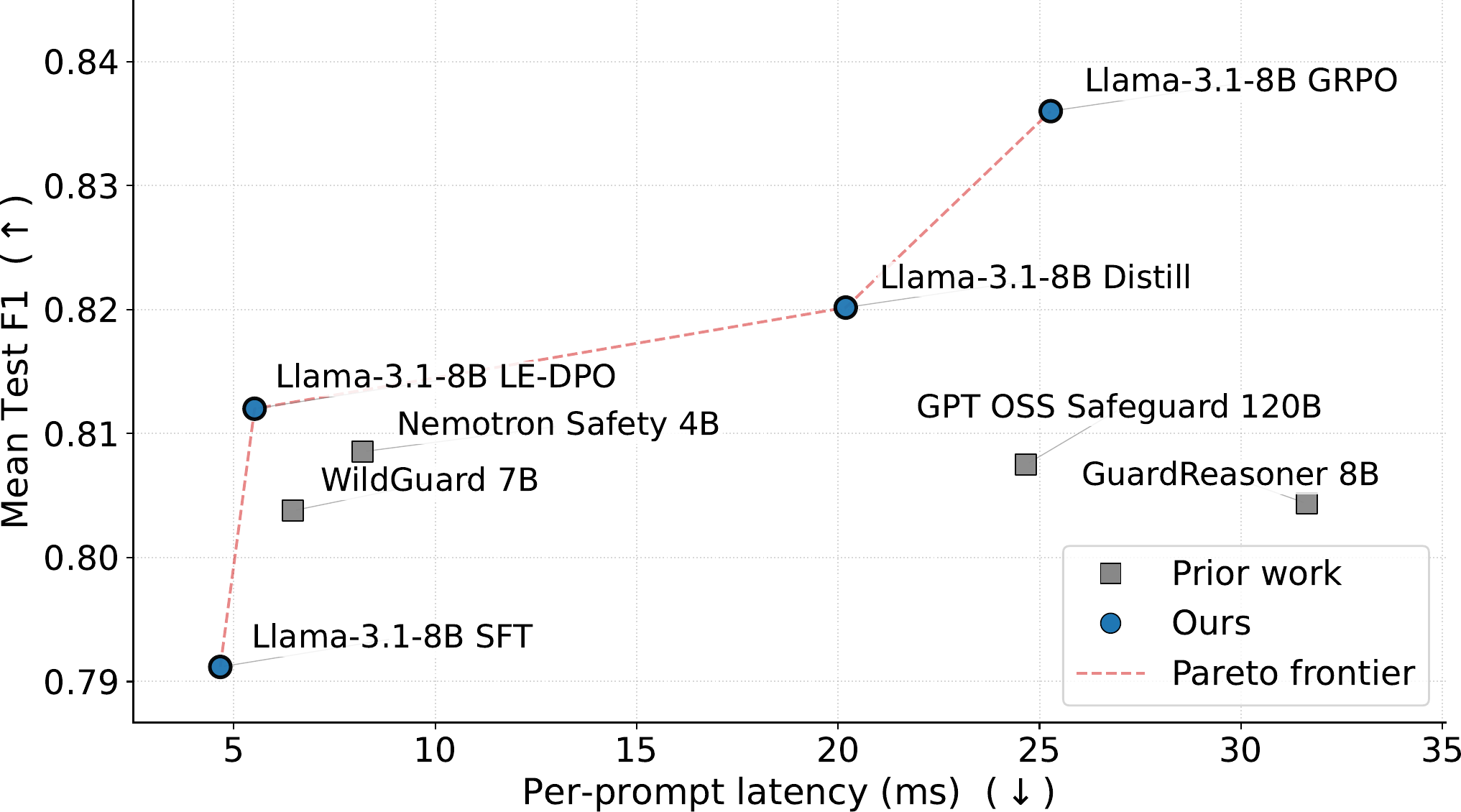
We argue that safety classifiers should model user intent as an explicit signal between the prompt and the final label. To study this, we introduce AIMS, a human-annotated dataset of 1,724 difficult safety prompts, each paired with an intent description and harm label. We use AIMS to evaluate intent-aware training across supervised fine-tuning, preference learning, reasoning distillation, and reinforcement learning. Despite its size, AIMS enables competitive safety classifiers across training regimes: DPO from model-generated intent errors improves over SFT, and intent-conditioned distillation outperforms reasoning-only distillation in most teacher–student pairs. Most notably, directly rewarding intent faithfulness with GRPO yields the strongest average performance across five external safety benchmarks, while our intent-aware models form the inference latency–F1 Pareto frontier. These results show that faithful intent modeling is a compact, high-quality supervision signal for more robust safety classifiers.
@misc{ferrao2026paved,
title = {Paved with True Intents: Intent-Aware Training Improves LLM Safety Classification Across Training Regimes},
author = {Ferrao, Jeremias and M{\"u}ller-Hof, Niclas and S{\^i}rbu, Iustin and Rebedea, Traian and Ziser, Yftah},
year = {2026},
eprint = {XXXX.XXXXX},
archivePrefix = {arXiv},
primaryClass = {cs.CL}
}